My Role GAN Architecture
Network Training
Random Sampling (w/ scaled random sampling)
The Team Xiangyu Peng
Alyssa Scheske
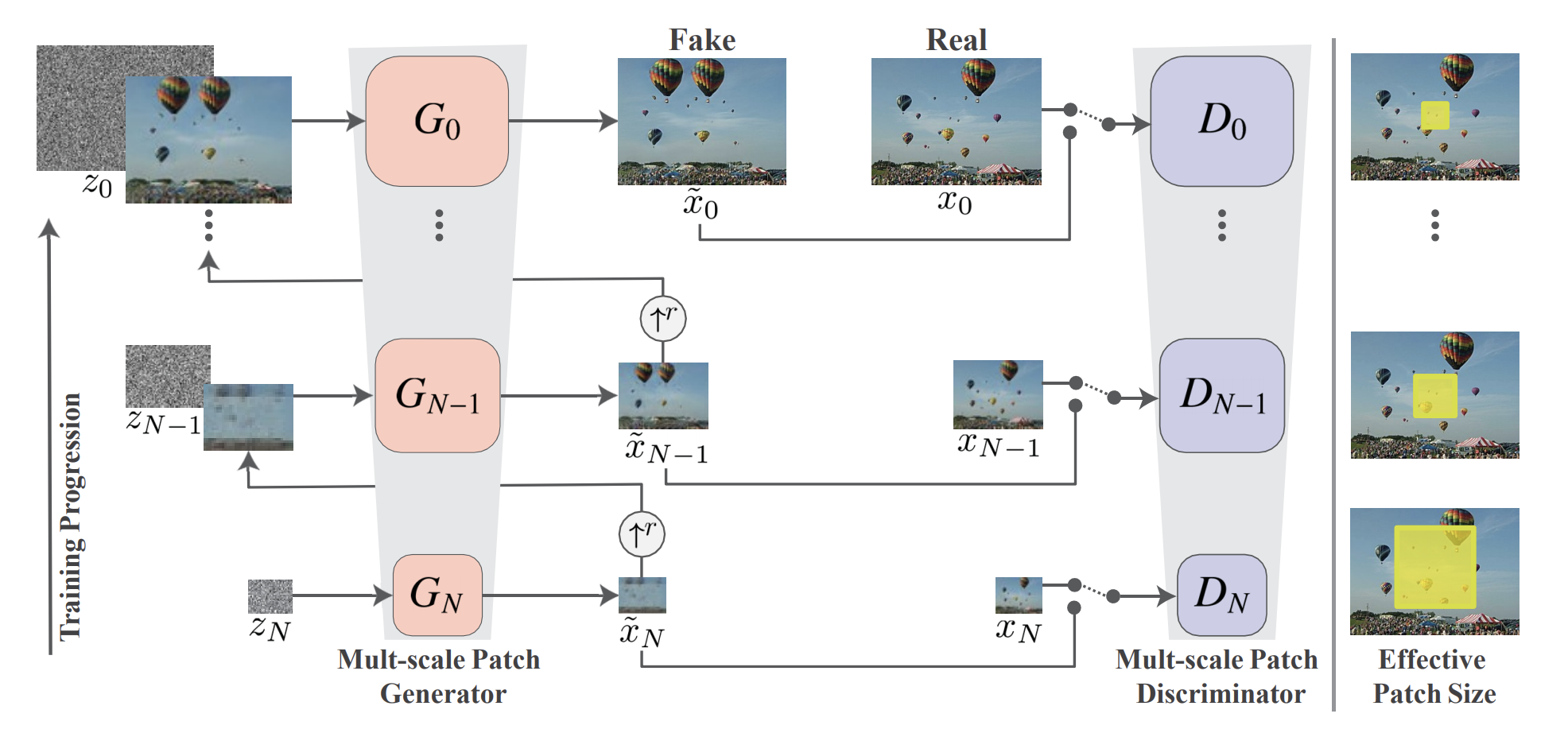
Generate unconditional realistic images from a single natural input image with akin quality to state-of-the art Generative Adversarial Networks (GANs) trained on complete classes of datasets. During my last semester at University of Michigan, I worked with the team to replicate the original SinGAN paper as part of the final project for my Coumputer Vision course. SinGAN learns the internal patch distribution within the image and then creates good quality samples which carry the same visual content as the original image. The generated samples are very diverse yet maintain the global structure and fine textures of the image. Being unconditional, SinGAN can generate new samples from pure noise. SinGAN has a training time of about 40-60 mins as tested on Google Collab with GPU usage which is a huge plus considering that the trained model can be used perform a wide variety of image manipulation tasks.
One of the basic functionality of SinGAN is to generate fake images that are hard to distinguish from the real one. SinGAN can generate fakes of variable size and aspect ratio by just changing the size of the input noise map. When generating fakes, the model produces new structures while still maintaining the visual content of the original image. Interestingly, SinGAN is not only able to preserve reflections but in many cases even synthesize it
Can you identify the real images from the fake ones? Below is a gallery of a mix of samples generated from sinGAN. Guess whether an image is real or a fake and move your mouse cursor over the image to find whether you were right or wrong!